复现 / 数据探索06 / 18
先确认数据特征和热销中心,再决定后续从哪些层级解释结果
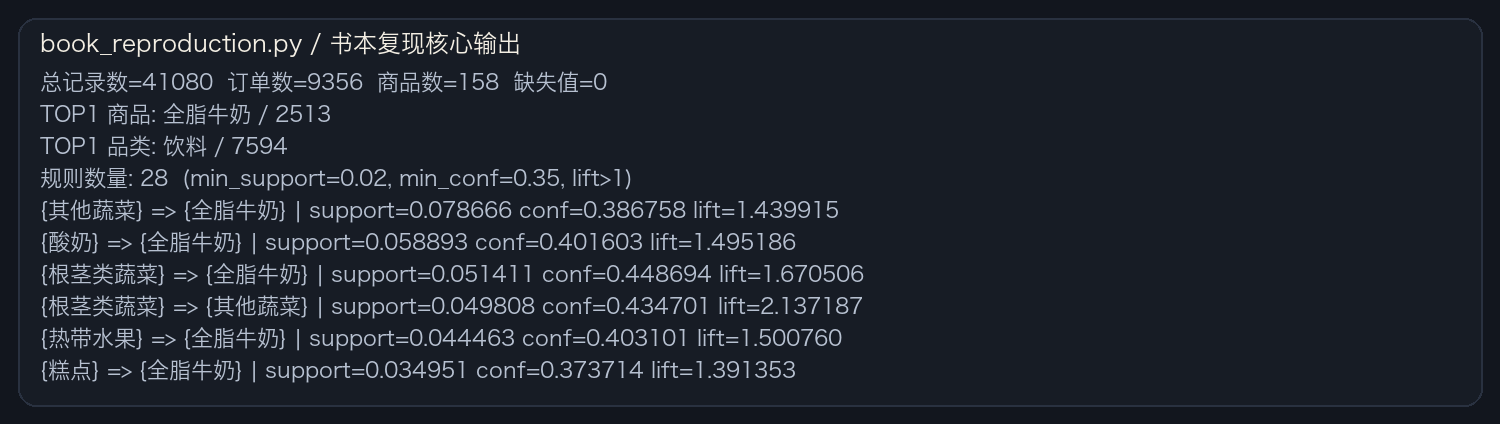
运行截图首先给出数据规模与规则总量,属于后续所有分析的基础口径。
流程解析
这一段先做 数据读取、info 查看 和 商品销量聚合。目的不是预测销量,而是找出哪个商品在购物篮网络中最可能成为核心节点。
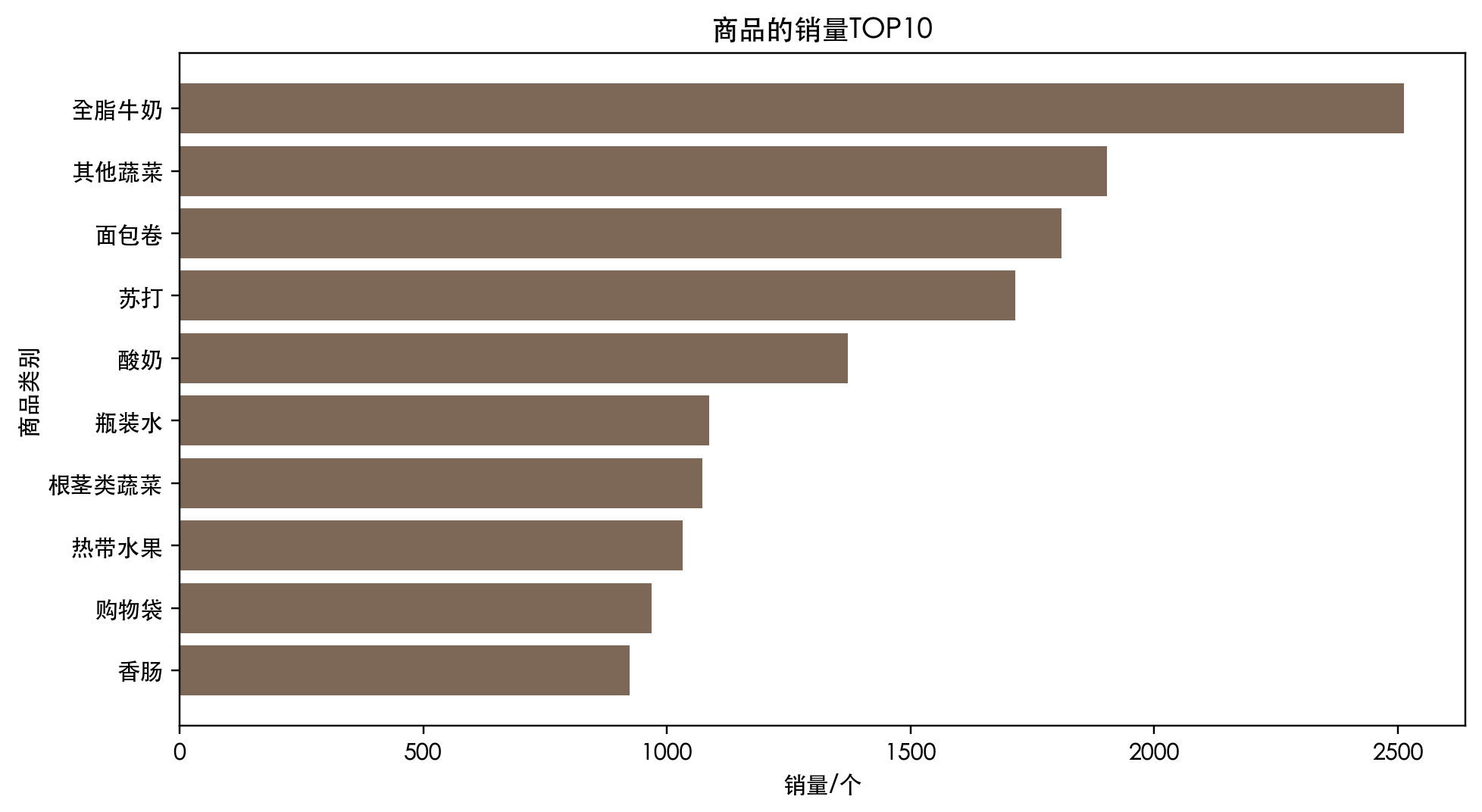
当前数据下,全脂牛奶、其他蔬菜、面包卷、苏打、酸奶是销量最高的五类商品。
结果含义
- 热销商品不等于强关联商品,但往往是后续规则的高频后件。
- 像全脂牛奶这样的中心商品,很容易在多条规则中重复出现。
- 这也解释了为什么后面需要做规则筛选,而不是只堆一张规则表。
复现 / 结构分析07 / 18
商品层和品类层要分开看,这决定了后续建议是“补货”还是“陈列”
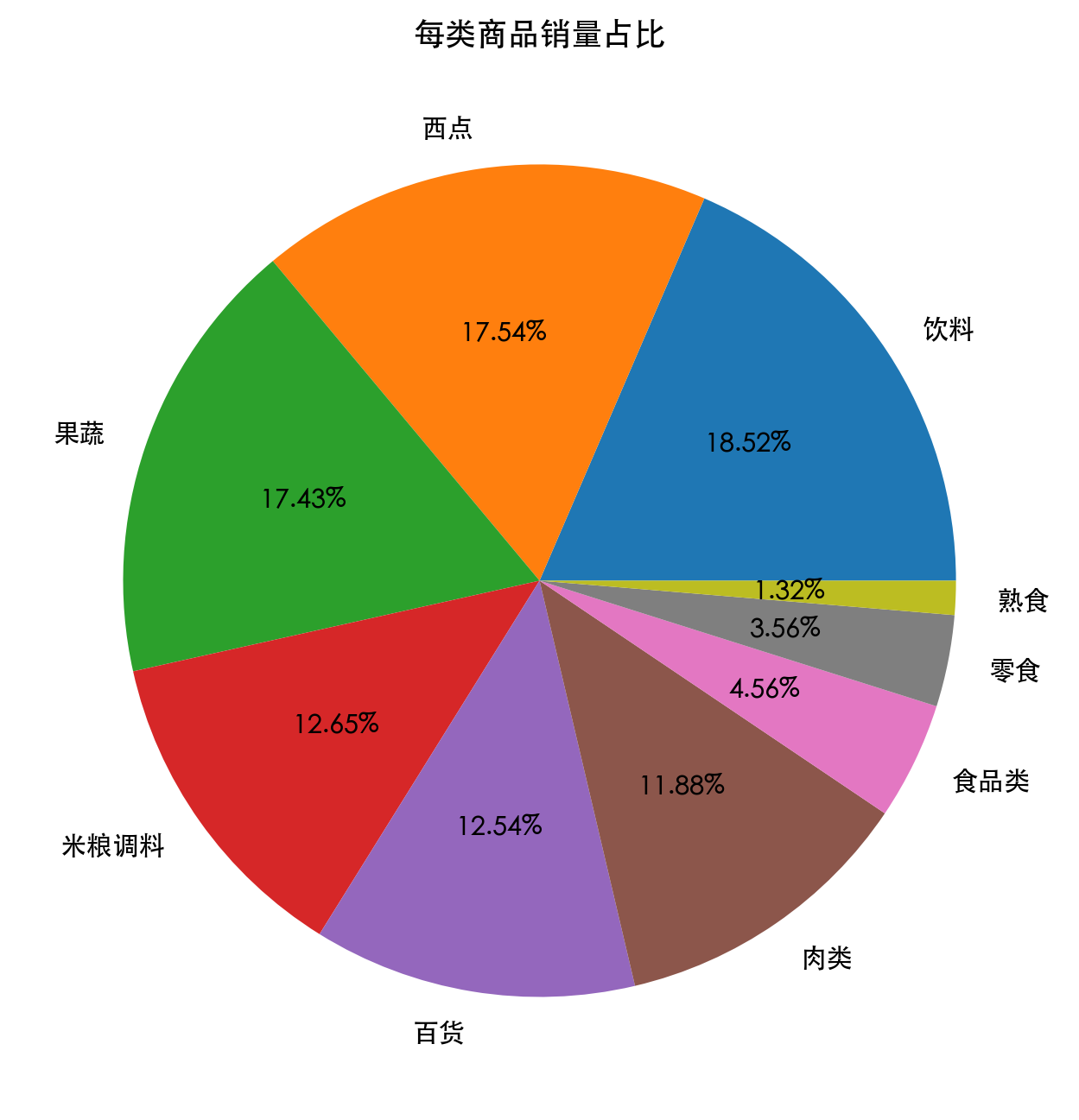
品类层视角下,饮料、西点、果蔬三类销量最接近,是零售篮子中的核心结构。
流程解析
这一步将销量表与品类映射表合并,再对 Types 聚合。原本分散的单品销量被提升为品类结构,适合从经营资源配置角度解释。
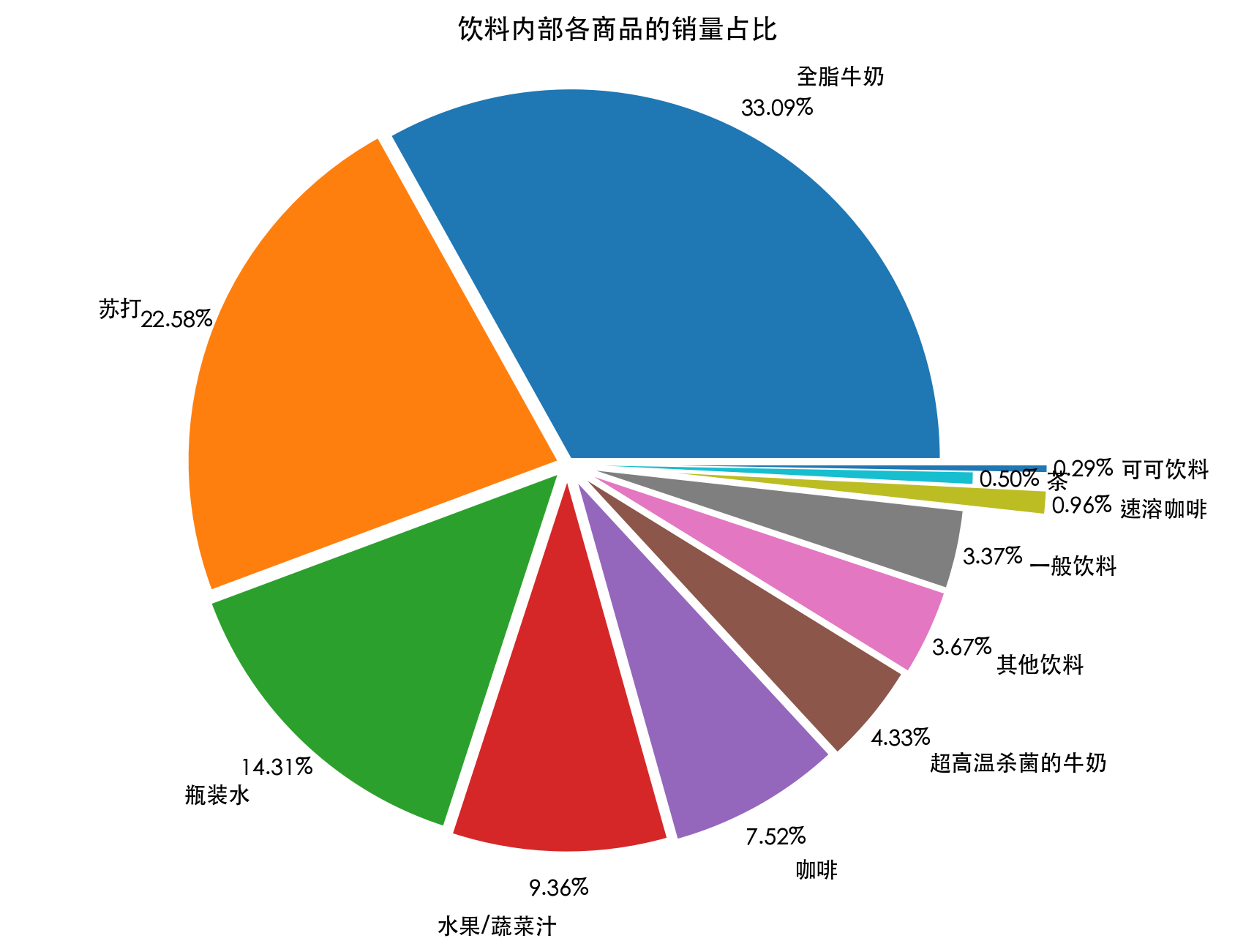
在饮料内部,全脂牛奶占比最高,说明其既是热销商品,也可能成为后续联动销售的核心后件。
经营含义
- 商品级结论更适合做补货、单品促销和捆绑。
- 品类级结论更适合做货架区位和区域陈列。
- 因此后面加入品类级规则不是重复建模,而是补一个更接近经营动作的解释层。
复现 / 规则输出10 / 18
在书本参数下,当前数据共输出 28 条有效规则,结果具有明显中心商品特征
当前 CSV 的复现结果
在 support=0.02、confidence=0.35、lift>1 的筛选下,最终得到 28 条 规则。代表性规则如下:
| lhs | rhs | support | confidence | lift |
|---|---|---|---|---|
| {其他蔬菜} | {全脂牛奶} | 0.078666 | 0.386758 | 1.439915 |
| {酸奶} | {全脂牛奶} | 0.058893 | 0.401603 | 1.495186 |
| {根茎类蔬菜} | {其他蔬菜} | 0.049808 | 0.434701 | 2.137187 |
运行结果说明代码逻辑已经完整复现,并且输出数量可控,适合进一步解释。
现象 1
全脂牛奶多次作为后件出现,说明它是购物篮中的中心商品。
现象 2
蔬菜之间的规则 lift 更高,说明部分共购关系更像同场景采购。
现象 3
规则条数不算多,但已经足够说明商品之间存在稳定的共购结构。
对比16 / 18
对比的重点不是算法名字,而是三种方案分别适合回答什么问题
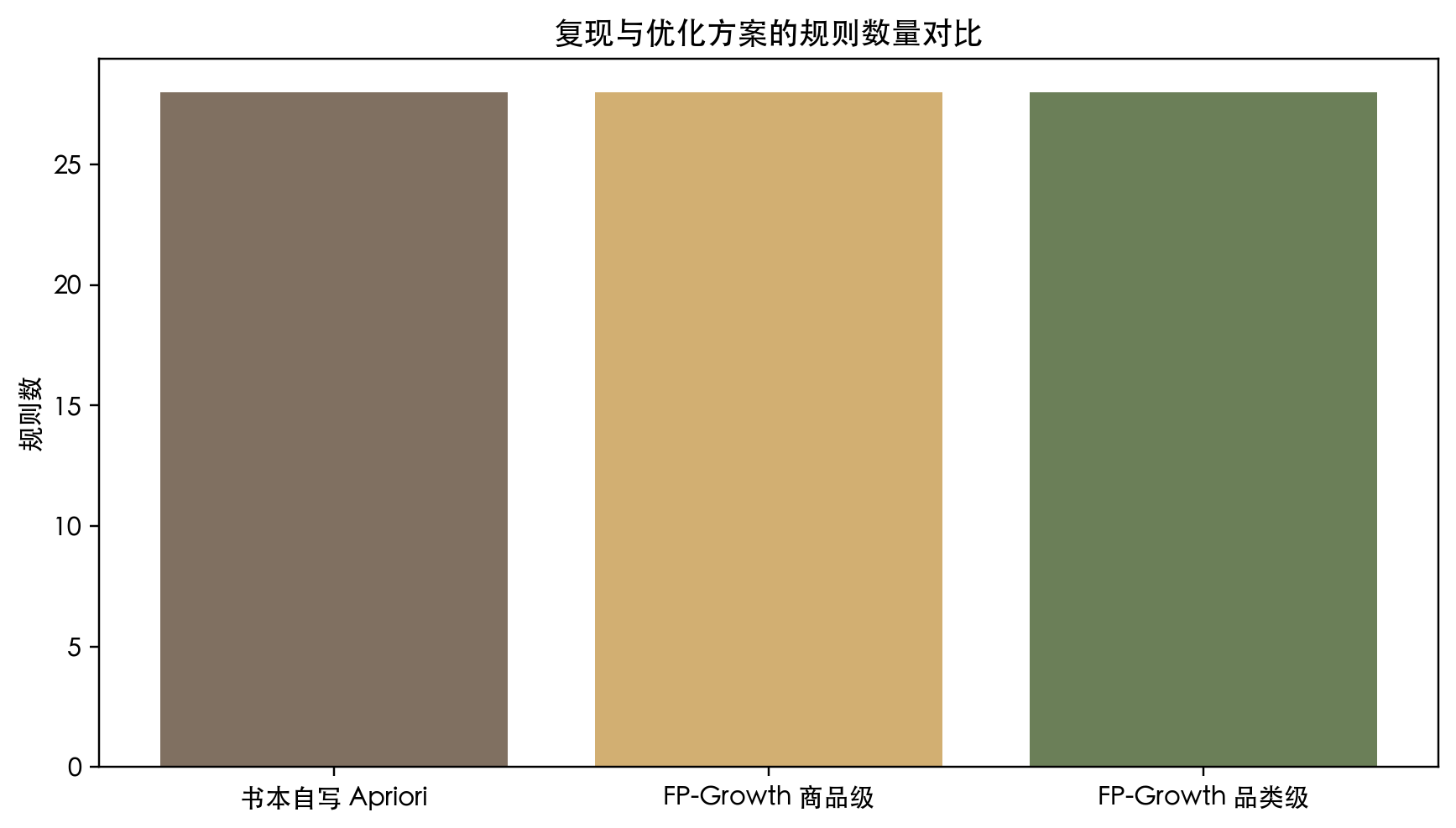
商品级 FP-Growth 与书本 Apriori 在当前阈值下都得到 28 条规则;品类级只有在重新设阈值后才具备可读性。
三种方案适用场景
| 方案 | 优势 | 更适合回答的问题 |
|---|---|---|
| 书本 Apriori | 最接近教材流程 | 是否完成原案例复现 |
| FP-Growth 商品级 | 效率更高,结果一致 | 哪些单品存在稳定共购 |
| FP-Growth 品类级 | 解释层级更高 | 哪些品类组合值得陈列与联促 |
对比结论
- 若目标是课程复现,应保留商品级结果作为基线。
- 若目标是经营解释,应优先使用品类级规则进行表达。
- 二者不是互相替代,而是分别服务于“验证”和“决策”。
决策18 / 18
综合结论:商品级结果用于复现验证,品类级结果用于经营决策
模型选择结论
商品级 Apriori / FP-Growth 适合用于验证书本案例、说明单品共购关系。
品类级 FP-Growth 更适合用于支持货架布局、区域陈列和组合促销等经营动作。
建议 1:把高频中心商品放在显眼位置
全脂牛奶、酸奶、其他蔬菜相关规则最集中,应作为核心补货和重点陈列商品。
建议 2:做“果蔬 + 饮料 + 米粮/肉类”联合陈列
品类级规则表明顾客在这些品类之间存在稳定联动,可做家庭采购场景化摆放。
建议 3:把单品规则和品类规则分层使用
商品级用于捆绑推荐,品类级用于货架区位和促销主题,不要混用。
综合结论
- 已完成关联规则建模流程的完整复现。
- 识别出数据版本差异及结果表达层级的局限。
- 通过 FP-Growth 与品类级规则提升了结果的经营解释力。
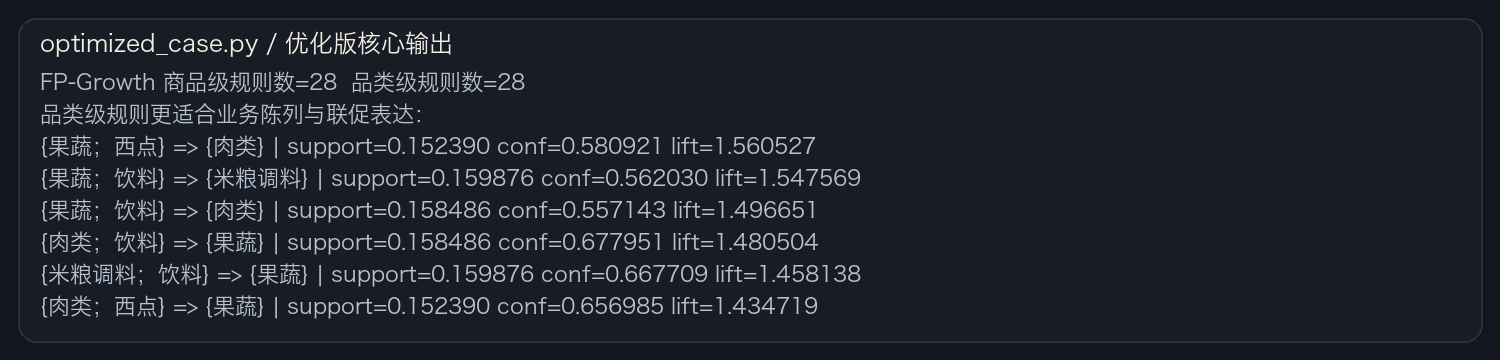
优化版终端输出展示了改进模型在当前参数下的结果表现。
结论总结
购物篮分析的核心价值 在于从共购关系中识别稳定消费场景,并将其转换为可执行的陈列、联促和补货策略。